
รายละเอียดโมดูล รุ่นที่ 2 ปี 2563
ภาพรวมของหลักสูตร
ลำดับการเรียน
การเรียนในส่วนนี้จะเป็นการเขียนโปรแกรมภาษาไพทอนสำหรับงานวิทยาศาสตร์ข้อมูล เพื่อให้สามารถนำไปใช้เป็นเครื่องมือช่วยในการประมวลผลข้อมูล วิเคราะห์ข้อมูลเบื้องต้น การเตรียมข้อมูล รวมถึงการนำไปต่อยอดใช้ร่วมกับกระบวนการเรียนรู้ของเครื่องได้
เนื้อหา (Contents) :
- การเขียนโปรแกรมภาษา Python เบื้องต้น
- การจัดการข้อมูลด้วย Dataframe
- การทำให้เห็นภาพ (Data visualization)
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- เขียนโปรแกรมภาษา python เบื้องต้นได้
- เลือกชนิดของการเก็บข้อมูลที่เหมาะสมกับข้อมูลได้
- ประยุกต์ใช้ฟังก์ชันในแพ็คเกจที่สร้างไว้สำหรับการประมวลผลข้อมูลโดยเฉพาะได้
- นำข้อมูลมาแสดงในรูปแบบกราฟฟิกที่ช่วยในการทำความเข้าใจวิเคราะห์ข้อมูลได้
ความรู้ก่อนเรียน (Prerequisite knowledge) : ไม่มี
เมื่อมีปัญหาที่ต้องการแก้ การระบุปัญหาให้ชัดเจนจะช่วยให้การเลือกวิธีการแก้ปัญหาได้อย่างเหมาะสม และที่สำคัญที่สุดคือการเลือกข้อมูลที่เหมาะสมมาช่วยในการวิเคราะห์เพื่อแก้ปัญหานั้น โมดูลนี้จะได้เรียนรู้ตั้งแต่การระบุปัญหา ขอบเขตของปัญหา การพิจารณาข้อมูลที่คิดว่าจะช่วยให้การวิเคราะห์ข้อมูลเป็นไปอย่างมีประสิทธิภาพ การสกัดคุณลักษณะที่ต้องการเพิ่มเพื่อนำมาพิจารณาความสำคัญ รวมถึงแนวทางในการประเมินความสำเร็จของการวิเคราะห์ข้อมูล
เนื้อหา (Contents) :
- ปัญหาและลักษณะข้อมูลที่ใช้วิธีการเรียนรู้ของเครื่อง
- การสกัดและการเลือกคุณลักษณะที่สำคัญ
- การวิเคราะห์ feature ของข้อมูลที่มีโอกาสมีผลต่อการวิเคราะห์ทั้งทางตรงและทางอ้อม
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- กำหนดเป้าหมายของปัญหาที่จะให้กระบวนการเรียนรู้ของเครื่องเรียนรู้จากข้อมูลได้อย่างชัดเจน
- แยกแยะความแตกต่างของวิธีเรียนรู้ของเครื่องแบบไม่มีผู้สอนและแบบมีผู้สอนได้
- เลือกคุณลักษณะที่มีผลต่อการวิเคราะห์ทั้งทางตรงและทางอ้อมด้วยกระบวนการที่เหมาะสม
ความรู้ก่อนเรียน (Prerequisite knowledge): ไม่มี
โมดูลนี้เป็นการเรียนรู้และฝึกสร้างแบบจำลองการทำนายข้อมูลที่มีค่าต่อเนื่อง โดยเริ่มจากการประเมินคุณลักษณะที่สำคัญกับการทำนาย เพื่อให้ได้แบบจำลองที่มีประสิทธิภาพดีที่สุด รวมถึงวิธีการฝึก วิธีการประเมิน และวิธีการนำเสนอผลของการวิเคราะห์เพื่อให้สามารถนำไปใช้กับสถานการณ์จริงได้อย่างมั่นใจ
เนื้อหา (Contents) :
- การทำให้ข้อมูลอยู่ในมาตรฐานเดียวกัน
- แบบจำลองเพื่อทำนายข้อมูลที่มีค่าต่อเนื่อง
- วิธีการวัดประสิทธิภาพของผลการทำนาย
- ไปป์ไลน์ของการสร้างแบบจำลองเปิดทำนายข้อมูลที่มีค่าต่อเนื่อง
- การป้องกันและตรวจสอบการเกิด overfitting และ underfitting ในขณะฝึก Machine Learning model
- การแบ่งข้อมูลเพื่อใช้ในการตรวจสอบประสิทธิภาพ และจำลองการใช้งานจริง
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ประเมิน feature ที่มีความสำคัญต่อการตัดสินใจสำหรับการทำนายค่าต่อเนื่องได้
- ฝึกแบบจำลองการเรียนรู้ของเครื่องด้วยวิธีและกระบวนการที่เหมาะสมที่จะช่วยให้ผลของการฝึกใกล้เคียงกับการนำไปใช้งานจริงมากที่สุด
- เลือกตัวแบบในการทำนายโดยใช้วิธีการประเมินจากผลลัพธ์การเรียนรู้ที่เหมาะสม
- แสดงผลและตีความผลการทำนายโดยใช้วิธีการทำให้เห็นภาพและการบรรยายที่เหมาะสม
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 01: การเตรียมข้อมูล การสกัดและการเลือกคุณลักษณะ (Data Preprocessing, Feature extraction and selection)
ปัจจุบันการใช้ AI ช่วยตัดสินใจเริ่มเข้ามามีบทบาทในชีวิตประจำวันมากขึ้นเรื่อย ๆ Machine Learning เป็นหนึ่งในเบื้องหลังที่สำคัญของความสำเร็จนั้น การสร้างแบบจำลองที่มีประสิทธิภาพ อาจต้องทำหลายขั้นตอน หลายรูปแบบ เพื่อเลือกรูปแบบที่ดีที่สุด ในโมดูลนี้จะช่วยให้เข้าใจ และสามารถสร้างแบบจำลองเพื่อทำนายประเภทของข้อมูลได้อย่างมีประสิทธิภาพ มีวิธีการวัดที่ชัดเจนในแต่ละขั้นตอนไม่ว่าจะเป็นการเลือกคุณลักษณะที่สำคัญ การเลือกโมเดล การประเมินผลการทำนาย การตีความหมายของโมเดลและผลการทำนาย ซึ่งทั้งหมดนี้จะได้ฝึกปฏิบัติทั้งเครื่องมือที่ใช้กับข้อมูลทั่วไปและเครื่องมือที่ใช้สำหรับข้อมูลขนาดใหญ่
เนื้อหา (Contents) :
- การเลือก feature ที่สําคัญต่อการตัดสินใจ
- แบบจำลองการเรียนรู้ของเครื่องแบบต่าง ๆ
- การวิเคราะห์แบบจำลองเพื่อทำข้อมูลให้อยู่ในรูปมาตรฐานเดียวกัน
- การวัดประสิทธิภาพของแบบจำลองจากผลการทำนาย
- ไปป์ไลน์ของการสร้างแบบจำลองเปิดทํานายประเภทของข้อมูล
- การป้องกันเเละการตรวจสอบการเกิด overfitting และ underfitting ขณะฝึกแบบจำลอง
- การแบ่งข้อมูลเพื่อตรวจสอบประสิทธิภาพและจําลองการใช้งานจริง
- Visualization และการตีความผลการทำนายเพื่อการนำเสนอ
- การนำไปใช้กับข้อมูลใหม่ในอนาคต
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ประเมิน feature ที่มีความสำคัญต่อการตัดสินใจสำหรับการทำนายประเภทของข้อมูลได้
- ฝึกแบบจำลองการเรียนรู้ของเครื่องเพื่อทำนายประเภทของข้อมูลด้วยวิธีและกระบวนการที่จะช่วยให้ผลของการฝึกใกล้เคียงกับการนำไปใช้จริงมากที่สุด
- เรียกตัวแบบในการทำนายประเภทข้อมูลโดยใช้วิธีการประเมินที่เหมาะสมจากผลลัพธ์การเรียนรู้ได้
- แสดงผลและตีความผลการทำนายโดยใช้วิธีการทำให้เห็นภาพและการบรรยายที่เหมาะสมกับแบบจำลองต่าง ๆ ได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 01: การเตรียมข้อมูล การสกัดและการเลือกคุณลักษณะ (Data Preprocessing, Feature extraction and selection)
Module 05 การจัดตารางเวลา (Scheduling)
เรียนรู้เกี่ยวกับการจัดการตารางเวลาโดยใช้หลักการวางแผนงาน รวมถึงใช้หลักการทางการประมวลผลการฟ เพื่อวางแผนและจัดตารางเวลาของงานที่มีความสัมพันธ์กัน และมีเงื่อนไขที่หลากหลาย
เนื้อหา (Contents) :
- Introduction to Planning and Scheduling
- Planning Principles
- Algorithms for Planning
- Planning Graphs
- Analysis of Planning Approaches
- Scheduling Principles
- Time, Schedules, and Resources
- Scheduling Algorithms
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ประยุกต์ใช้ในการจัดตารางเวลาของงานที่เกี่ยวข้องกันได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 01: การเตรียมข้อมูล การสกัดและการเลือกคุณลักษณะ (Data Preprocessing, Feature extraction and selection)
เรียนรู้การตรวจหาข้อมูลผิดปกติทั้งจากข้อมูลทั่วไปและสัญญาณจากอุปกรณ์ตรวจวัดอัตโนมัติ เพื่อให้สามารถจับความผิดปกติ การรับทราบปัญหาอย่างทันท่วงที รวมถึงการวางแผนซ่อมบำรุง เพื่อป้องกันปัญหาที่อาจจะเกิดขึ้นตามมาในอนาคต ในบางกรณีข้อมูลที่บันทึกไว้อาจมีข้อมูลตัวอย่างของความผิดปกติที่เคยเกิดขึ้น แต่ในบางกรณีมีเฉพาะข้อมูลที่ปกติ ซึ่งสามารถนำมาฝึกโมเดลการเรียนรู้ของเครื่องโดยใช้โมเดลที่เหมาะสมเพื่อให้สามารถนำไปใช้ได้อย่างมีประสิทธิภาพ
เนื้อหา (Contents) :
- สำรวจข้อมูลด้วยค่าทางสถิติและใช้ Visualization
- การระบุข้อมูลผิดปกติ (Anomaly detection) แบบคุณลักษณะเดียว (Univariate) และหลายคุณลักษณะ (Multivariate)
- การระบุข้อมูลผิดปกติ (Anomaly detection) โดยใช้ Machine learning
- การแสดงผลการวิเคราะห์ด้วยการวิเคราะห์องค์ประกอบหลัก (Principle Component Analysis: PCA)
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ทำการวิเคราะห์เพื่อระบุข้อมูลผิดปกติจากข้อมูลทั่วไปได้โดยใช้หลักการทางสถิติได้
- สร้างโมเดลทางการเรียนรู้ของเครื่อง (Machine learning model) ที่สามารถนำมาใช้ตรวจจับความผิดปกติได้โดยการฝึกโมเดลทั้งจากข้อมูลที่มีเฉพาะสถานการปกติอย่างเดียว และการฝึกโมเดลจากข้อมูลที่มีทั้งข้อมูลปกติและผิดปกติอยู่ด้วยกัน
- แสดงผลการวิเคราะห์ข้อมูลที่มีหลายมิติด้วยการลดจำนวนมิติเพื่อการแสดงผลที่เหมาะสมได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 01: การเตรียมข้อมูล การสกัดและการเลือกคุณลักษณะ (Data Preprocessing, Feature extraction and selection)
เรียนรู้หลักการบันทึกภาพ และหลักการแทนค่าสีด้วยแบบจำลองแบบต่าง ๆ เพื่อให้สามารถนำมาประยุกต์ใช้กับการประมวลผลภาพได้อย่างเหมาะสม เรียนรู้การปรับปรุงคุณภาพของภาพไม่ว่าจะเป็นความสว่าง ความคมชัด การลดสัญญาณรบกวน การเน้นองค์ประกอบที่เป็นประโยชน์ต่อการวิเคราะห์ โดยใช้เทคนิคขั้นสูงเพื่อให้ได้ภาพที่พร้อมสำหรับการใช้งานเฉพาะทาง
เนื้อหา (Contents) :
- ภาพและการบันทึกภาพใน computer
- แบบจำลองสี (Color model)
- การประมวลผลภาพเบื้องต้น
- การประมวลผลภาพที่อยู่บนโดเมนของความถี่ (Frequency domain)
- การทำคอนโวลูชัน
- การประมวลผลภาพเพื่อเน้นองค์ประกอบที่ต้องการ
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ใช้หลักการวิเคราะห์สีเพื่อวิเคราะห์การปลอมปนของวัตถุดิบที่แยกได้ด้วยสีได้
- สามารถปรับปรุงคุณภาพของภาพให้องค์ประกอบที่สนใจเด่นชัดขึ้นมาได้
- ใช้หลักการการประมวลผลภาพเพื่อเน้นองค์ประกอบที่ต้องการเพื่อวิเคราะห์การปลอมปนของวัตถุดิบที่มีความซับซ้อนได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
- ไม่มี
เรียนรู้เกี่ยวกับการแยกองค์ประกอบของภาพดิจิทัล เพื่อนำองค์ประกอบที่สนใจไม่ว่าจะเป็นวัตถุต่างชนิด หรือภาพพื้นหลัง มาใช้งานสำหรับการวิเคราะห์ต่อ ซึ่งสามารถทำได้หลากหลายวิธีขึ้นอยู่กับความซับซ้อนขององค์ประกอบในภาพ ตั้งแต่ใช้วิธีแบบไม่มีผู้สอน (Unsupervised) ไปจนถึงการเรียนรู้เชิงลึก (Deep learning)
เนื้อหา (Contents) :
- การแยกส่วนประกอบที่สนใจด้วยค่า Threshold (Thresholding image segmentation)
- การแยกส่วนประกอบโดยการใช้การเรียนรู้ของเครื่องแบบไม่มีผู้สอน (Unsupervised machine learning)
- การแยกส่วนประกอบโดยการใช้การเรียนรู้ของเครื่องแบบไม่มีผู้สอน (Supervised machine learning)
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ใช้หลักการการแยกส่วนประกอบเพื่อวิเคราะห์การปลอมปนของวัตถุดิบได้
- ใช้ตรวจหาวัตถุที่สนใจในภาพได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 07 การประมวลผลภาพเบื้องต้น (Basic image processing)
การตรวจจับใบหน้าเป็นหนึ่งในวิธีการตรวจจับวัตถุในภาพโดยใช้วิธีแบบมีผู้สอน สามารถใช้ได้หลายวิธีซึ่งมีประสิทธิภาพขึ้นอยู่กับสภาพแวดล้อมของการนำไปใช้ เนื้อหาส่วนนี้จะได้เรียนรู้วิธีการต่าง ๆ และสถานการณ์ที่เหมาะสมกับการใช้วิธีการเหล่านั้น
เนื้อหา (Contents) :
- การตรวจจับใบหน้าโดยใช้แม่แบบ (Template matching)
- การตรวจจับใบหน้าโดยใช้ Haarcascade
- การตรวจจับใบหน้าโดยใช้ Deep learning
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ประยุกใช้เทคนิคการตรวจจับใบหน้ากับภาพนิ่งและภาพเคลื่อนไหวได้
- สกัดใบหน้าของบุคคลที่อยู่ในภาพทั้งภาพนี่งและภาพเคลื่อนไหวได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 07 การประมวลผลภาพเบื้องต้น (Basic image processing)
การแยกประเภทภาพสามารถนำไปประยุกต์ใช้ได้อย่างหลากหลายในปัจจุบันตั้งแต่การแยกองค์ประกอบของภาพ การรู้จำวัตถุ การรู้จำใบหน้าและอารมณ์ ไปจนถึงการทำรถขับเคลื่อนอัตโนมัติ เนื้อหาส่วนนี้จะได้เรียนรู้การสร้างและนำโมเดลทางการเรียนรู้ของเครื่องมาใช้กับแยกประเภทภาพ ซึ่งหากนำมาใช้ร่วมกับการทำนายหรือแยกประเภทขององค์ประกอบในภาพที่แยกออกมาแล้วก็จะสามารถประยุกต์ใช้งานได้อย่างหลากหลาย
เนื้อหา (Contents) :
- การเรียนรู้จากตัวอย่าง (instance based learning)
- การเรียนรู้โดยใช้โมเดลการเรียนรู้ของเครื่องแบบมีผู้สอน (Supervised machine learning)
- การเรียนรู้โดยใช้ Deep learning
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- แยกประเภทของภาพโดยใช้ข้อมูลภาพทั้งภาพหรือข้อมูลองค์ประกอบในภาพได้
- สร้างโมเดลการรู้จำใบหน้าได้
- สร้างโมเดลการแยกประเภทอารมณ์จากใบหน้าได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 07 การประมวลผลภาพเบื้องต้น (Basic image processing)
เมื่อข้อมูลเกิดขึ้นอย่างรวดเร็ว มีความหลากหลายขึ้นเนื่องจากเทคโนโลยีในการตรวจวัดและจัดเก็บเข้าถึงได้ง่ายขึ้น ทำให้เกิดข้อมูลปริมาณมหาศาลจนส่งผลให้เกิดปัญหาขึ้นทั้งการจัดเก็บ การประมวลผลเพื่อสรุปผลทำความเข้าใจ และการวิเคราะห์ข้อมูลโดยใช้การเรียนรู้ของเครื่อง โมดูลนี้จะเรียนรู้เกี่ยวกับเครื่องมือที่ช่วยในการจัดการกับข้อมูลมหาศาลเหล่านั้นได้อย่างง่ายดาย
เนื้อหา (Contents) :
- Hadoop และเครื่องมือที่ใช้งานร่วมกัน
- ระบบไฟล์แบบกระจายของ Hadoop (Hadoop Distributed File System: HDFS)
- เฟรมเวิร์คในการประมวลผลข้อมูลแบบ MapReduce
- การใช้งาน Hadoop as a service บน Cloud
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- อธิบายการทำงานของ Hadoop และองค์ประกอบต่าง ๆ ได้พอสังเขป
- สร้าง Hadoop cluster เพื่อใช้ในการประมวลผล Big data บน cloud ได้
ความรู้ก่อนเรียน (Prerequisite knowledge) : ไม่มี
Apache Spark เป็นซอฟต์แวร์แบบโอเพ่นซอร์สที่ช่วยอำนวยความสะดวกในการประมวลผลข้อมูลขนาดใหญ่ ทำให้การทำงานในขั้นตอนต่าง ๆ ของการวิเคราะห์ข้อมูล เป็นไปอย่างราบรื่นและรวดเร็ว การเรียนรู้การใช้งาน Spark จึงเป็นประโยชน์อย่างยิ่งต่อการวิเคราะห์ข้อมูลขนาดใหญ่เพื่อให้สามารถวิเคราะห์ให้ได้ประโยชน์เชิงลึกจากข้อมูลนั้นมากที่สุดเท่าที่จะทำได้ โมเดลนี้จะได้เรียนรู้การดำเนินการกับข้อมูลในรูปแบบต่าง ๆ รวมถึงการใช้ Machine Learning Library ของ Spark เพื่อความคุ้นเคยกับการใช้เครื่องมือต่าง ๆ ช่วยในการวิเคราะห์ข้อมูล
เนื้อหา (Contents) :
- หลักการทำงานของ Spark
- Spark DataFrame
- การจัดการข้อมูลใน DataFrame
- Spark Machine learning library
เมื่อจบโมดูลแล้วผู้เรียนสามารถ (Learning Outcome):
- ใช้ transformation และ action ของ spark เพื่อประมวลผลข้อมูลที่เก็บอยู่บน Hadoop cluster ได้
- ประมวลผลข้อมูลโดยใช้ DataFrame API กับภาษา python ได้
- สร้างโมเดลการเรียนรู้ของเครื่องบน Big data ได้
ความรู้ก่อนเรียน (Prerequisite knowledge)
Module 11 Big data tool and integration
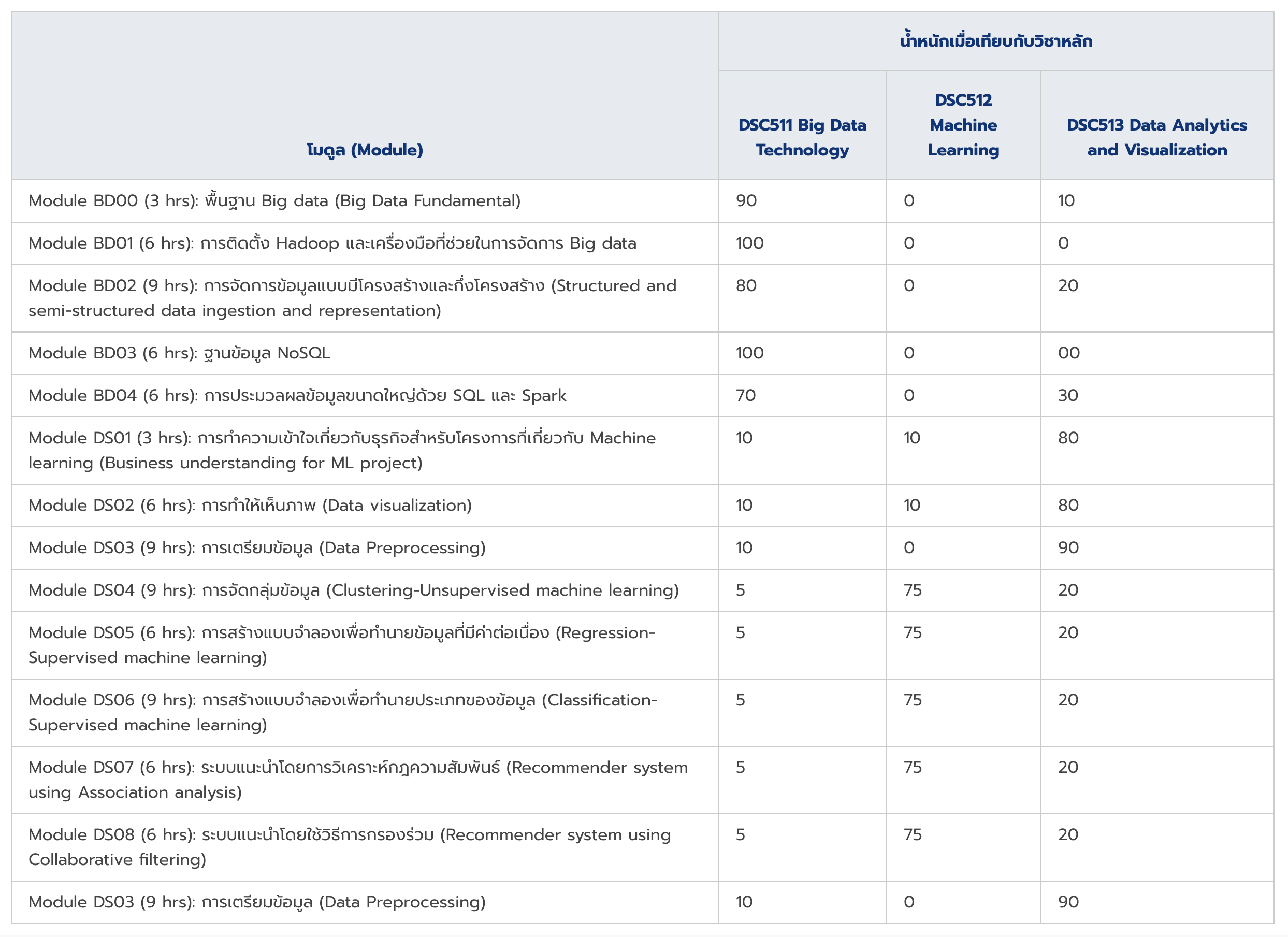
ภาพรวมของหลักสูตร
โมดูลกับวิชาเรียน
Advance data science tool

Visualization tool


Data ingestion and ETL tools
Other tool

ตารางการเรียนการสอนและการให้คำปรึกษา
ระยะเวลาเรียน
- ภาคทฤษฎีและปฏิบัติ ระหว่างวันที่ 11 กันยายน 2563 – 18 ธันวาคม 2563
- เรียนทุกวันศุกร์และวันเสาร์ เวลา 09.00 – 16.00 น. ห้องปฏิบัติการ คณะเทคโนโลยีสารสนเทศ มหาวิทยาลัยเทคโนโลยีพระจอมเกล้าธนบุรี
- Worked Integrated Learning (WIL)
- ผู้เรียนเรียนรู้แก้ปัญหาจากโจทย์จริงของสถานประกอบการที่สังกัด ณ สถานประกอบการเต็มเวลา
- จันทร์ – พฤหัสบดี (กันยายน 2563 – ธันวาคม 2563)
- ผู้สอนให้คำปรึกษาเพื่อร่วมแก้โจทย์ปัญหาจากสถานประกอบการ ตามนัดหมาย ทั้งหลังคลาสเรียนและการให้คำปรึกษาออนไลน์ผ่านทาง Microsoft Teams
ตารางการเรียนการสอนและการให้คำปรึกษา
- วันศุกร์ เวลา 00 – 16.00 น. ณ ห้อง ณ ห้อง Classroom 4/2 ชั้น 4
- วันเสาร์ เวลา 00 – 12.00 น. ณ ห้อง Training Learning Space ชั้น 2
- วันเสาร์ เวลา 13.00 – 16.00 น. ณ ห้อง Training I และ Training II,V ชั้น 1